他人の作ったクラス(昔だったら関数、サブルーチン)は、内容を100%近く理解していないと使えないという思い込みがある。もし本当にそうなら “numpy” も使えないんだけどね。
一方で、プログラムを一から自作するとまず最初からまともに動いたためしはないから、他人の作ったプログラムで動いてるのがあれば、極力流用したいというアタマもある。
つまり私の作るプログラムは、どっちにしろまともに動かないということだ。ほっとけや。
しかし 前回のエントリー で4セグメントLEDの機械学習プログラムを自作するにあたって、『ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装』(以下「テキスト」)P114~115 で定義されたクラス “TwoLayerNet” から、コードをたくさん流用した。だったらせっかくのクラスをわざわざ崩すことはないじゃないかと気づいたことを、前回の末尾で述べた。
そもそもクラスはコードを再利用するためのものだから、気づくのが遅いんだけど。でもコードを流用することによりコードの理解が進んだし、「動く」という事前確認にもなったから、それはそれでよかったのか。
“TwoLayerNet” は、テキストP118で、こんなふうに呼び出されている。
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
引数 “input_size” 、“hidden_size” 、“output_size” は、テキストの流儀に従って行列の形状を表記した場合の、入力 “x”、第1層重み “W1”、第2層重み “W2”、出力 “y” のそれぞれの数値に対応している。なお “x” と“y” のデータ数100は、プログラムの別の個所の「繰り返し(for)」によって実現する。

いっぽう4セグメントLEDの行列の形状は、次のようになる。
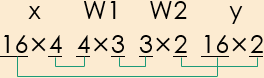
だったら “input_size” を784から4に、 “hidden_size”を50から3に、 “output_size” を10から2に変更するだけでいいじゃないかと思いつくことは、決して難しくはない(なおそれぞれの数値の意味は、理解しているつもりだがここでの説明は省略する)。
スポンサーリンク
次のようなコードで、実行できた。
import sys, os
sys.path.append(os.pardir)
import numpy as np
from two_layer_net import TwoLayerNet
network = TwoLayerNet(input_size=4, hidden_size=3, output_size=2)x = np.array([[1, 1, 1, 1],[0, 0, 1, 0],[1, 0, 0, 0]])
t = np.array([[1, 0], [0, 1], [0, 1]])
learning_rate = 1.0
前回同様 “x” は入力データ、 “t” は教師データだ。学習率 “leaning_rate” を1.0としたのも前回と同様だ。改造したのはこのくらいだ。
そして以下のコードを繰り返し [Ctrl] + [v] で Anaconda Prompt に貼り付けた。
network.predict(x)
np.argmax(network. predict(x), axis =1)
network.loss(x, t)
grad = network.numerical_gradient(x, t)
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
“network.predict” は推定値。今回も argmax (テキストP80)を噛ませた。
“network.loss” は損失である。
前回との違いは、for 文にディクショナリのキー 'W1'、 'b1'、 'W2'、 'b2' を使用することによって、重みとバイアスの更新が2行で記述できたことだ。こうした方が楽に決まってるが python の文法に不慣れなんですすみません。
貼り付け実行一回目。

二回目。

今回は34回目の貼り付けで正解が出た。

これだけでも満足度が高かったが(あくまで個人の感想)、ちょっと欲が出た。4セグメントLEDなんて実用性のないものではなく、7セグメントLEDの機械学習もやらせられないだろうかと。
* * *
7セグメントLEDに関しては、そんなに説明は要らないと思う。ネットで調べて、MSB(最上位ビット)からLSB(最下位ビットまでを、下記のように割り当てた。
あと下図は私がパワーポイントを用いて描いたものだが、普段我々が目にしている7セグメントLEDが、目立たぬところで工夫が凝らされているからであろう、デザイン的にいかに洗練されたものであるかに気づかされた。早く言えば自分で描いたものはイケてない。

入力データ “x” と教師データ “t” を、次のように定義する。もっとスマートな記述ができそうだが、欲は出さないでおく。
import numpy as np
x = np.array([\
[0, 1, 1, 1, 1, 1, 1], #0\
[0, 0, 0, 0, 1, 1, 0], #1\
[0, 1, 1, 0, 0, 0, 0], #1\
[1, 0, 1, 1, 0, 1, 1], #2\
[1, 0, 0, 1, 1, 1, 1], #3\
[1, 1, 0, 0, 1, 1, 0], #4\
[1, 1, 0, 1, 1, 0, 1], #5\
[1, 1, 1, 1, 1, 0, 1], #6\
[0, 0, 0, 0, 1, 1, 1], #7\
[1, 1, 1, 1, 1, 1, 1], #8\
[1, 1, 0, 1, 1, 1, 1]])#9t = np.array([\
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0], #0\
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0], #1\
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0], #1\
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0], #2\
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0], #3\
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0], #4\
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0], #5\
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0], #6\
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0], #7\
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0], #8\
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1] ])#9
今回の入力 “x”、第1層重み “W2”、第2層重み “W2”、出力 “y” の形状は、次のようにしてみた。

するとクラス “TwoLayerNet” の呼び出し方は、次のようになる。
import sys, os
sys.path.append(os.pardir)
from two_layer_net import TwoLayerNet
network = TwoLayerNet(input_size=7, hidden_size=11, output_size=10)learning_rate, step_num = 1.0, 100
学習率 “learning_rate” は1.0としてみた。今回は収束まで何百回も貼り付ける必要があったので、for文を2重にして繰り返し回数 “spep_num” を 100 としてみた。実は最初に試したときには、手動で何百回と貼り付けたのだが、全然苦にならなかった。だがさすがにそれを他人にまで勧めるわけにはいくまい。
network.predict(x)
np.argmax(network. predict(x), axis =1)
network.loss(x, t)for i in range(step_num):
grad = network.numerical_gradient(x, t)
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
初回の実行結果。推定値 “network.predict” のダンプがでかくなったので、argmax を使うありがたみが出たように感じた。

実行100回目。推定値を省略して argmax と損失 “network.loss” だけを貼る。

200回目。

300回目。ついに正解が出た!

繰り返し回数 “spep_num” を 100 ではなく 500 などにすると、最初の実行で正解が出る。だが処理に時間がかかり、結果が表示されるのに少し(何秒か)待たされる。
しかしそれもまたいいのだ。次の5章で誤差伝播法というのを導入して、高速化を図る必要性がよくわかるからだ。
* * *
期待通りの結果が出たことにより、さらに試してみたいことが次々とできた。よってこのシリーズは、今回で完結とする。尻切れトンボのような終わり方だが、やりたいことに限りはないので。

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
- 作者: 斎藤康毅
- 出版社/メーカー: オライリージャパン
- 発売日: 2016/09/24
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (16件) を見る